Do AI Agents Make ML Compilers Obsolete?
AI agents can now write GPU kernels and low level code on their own. That was supposed to make the ML compiler obsolete so why did the industry just spend billions doubling down on it?

When I first got into machine learning around 2019, I did what any self-respecting systems person would do. I ignored the tutorials and went straight to the guts. What is TensorFlow actually doing when I call model.fit()? What does PyTorch turn my nice Python code into before it hits the GPU?
What I found was a familiar layered cake. Python at the top. C++ in the middle. And at the very bottom, hand-written CUDA kernels doing the actual math on silicon. The same pattern computing has used since the 1950s: humans write something readable, and something else turns it into what the hardware actually wants.
Fast forward to two weeks ago. Google and Hugging Face ran the Fast Gemma Challenge1, where over 60 AI agents coordinated through a shared message board and autonomously optimized inference speed for Google’s Gemma 4 E4B model. Custom CUDA kernels, quantization strategies, speculative decoding. Over 127 tokens per second2, a substantial jump from the baseline.
Then yesterday, two pieces of news dropped within hours. Qualcomm announced it’s acquiring Modular3 for $3.9 billion. And OpenAI unveiled Jalapeno4, its first custom inference chip, co-developed with Broadcom. Both say something very specific about where this industry thinks the real value sits.
If AI agents can write and optimize kernels autonomously, do we still need ML compilers? I’ve been chewing on this for a while, and I think the answer will annoy people on both sides.
We’ve Had This Argument Before
In the 1950s, programming meant writing machine code. Binary sequences on punch cards. If you wanted to add two numbers on an IBM 704, you needed the exact opcode, the register layout, and a tolerance for suffering.
Then assembly language came along. ADD R1, R2 instead of 0x01 0x01 0x02. People thought this was plenty of abstraction.
When John Backus and his team at IBM shipped FORTRAN in 1957, the assembly programmers were not impressed. “It’ll be slower.” “You lose control.” “Real programmers don’t need this.”
FORTRAN code was slower at first. About 20% slower in early benchmarks. But FORTRAN programs were written in a fraction of the time, could be maintained by someone other than the original author, and improved with every compiler release. General Motors studies showed 5–10x productivity improvement over assembly. Within a decade, over half of all IBM computer code was FORTRAN-generated, and the “real programmers write assembly” crowd had moved on to arguing about whether COBOL was a real language.
C in the 1970s. C++ in the 1980s. Java in the 1990s. Same story every time. “Too slow, too abstract, you’re giving up control.” And every time, the abstraction won. The compilers got better. The people who insisted on doing things by hand either found new, harder problems to work on or got very good at complaining.
The exact same argument is playing out right now with ML compute. Fancier hardware, Twitter instead of Usenet, identical pattern. To understand why, you need to see how the ML compute stack is actually built.
The Two-Layer Cake
If you’ve written a neural network in PyTorch, you’ve probably written something like this:

Clean. Readable. You’re thinking about architecture, tensor shapes, data flow.
But when this runs on a GPU, that nn.Linear call becomes a matrix multiplication, and that multiplication becomes thousands of GPU threads reading from shared memory in specific patterns to avoid bank conflicts, using tensor cores when available, tiling the computation into blocks that fit the GPU’s cache hierarchy.
The actual kernel code looks nothing like Python:

This two-layer setup made sense. Researchers think in layers, attention heads, loss functions. Kernel engineers think in warps, shared memory, instruction-level parallelism. Different skill sets, different people. The researchers define models in Python. The kernel engineers write the compute in C and CUDA.
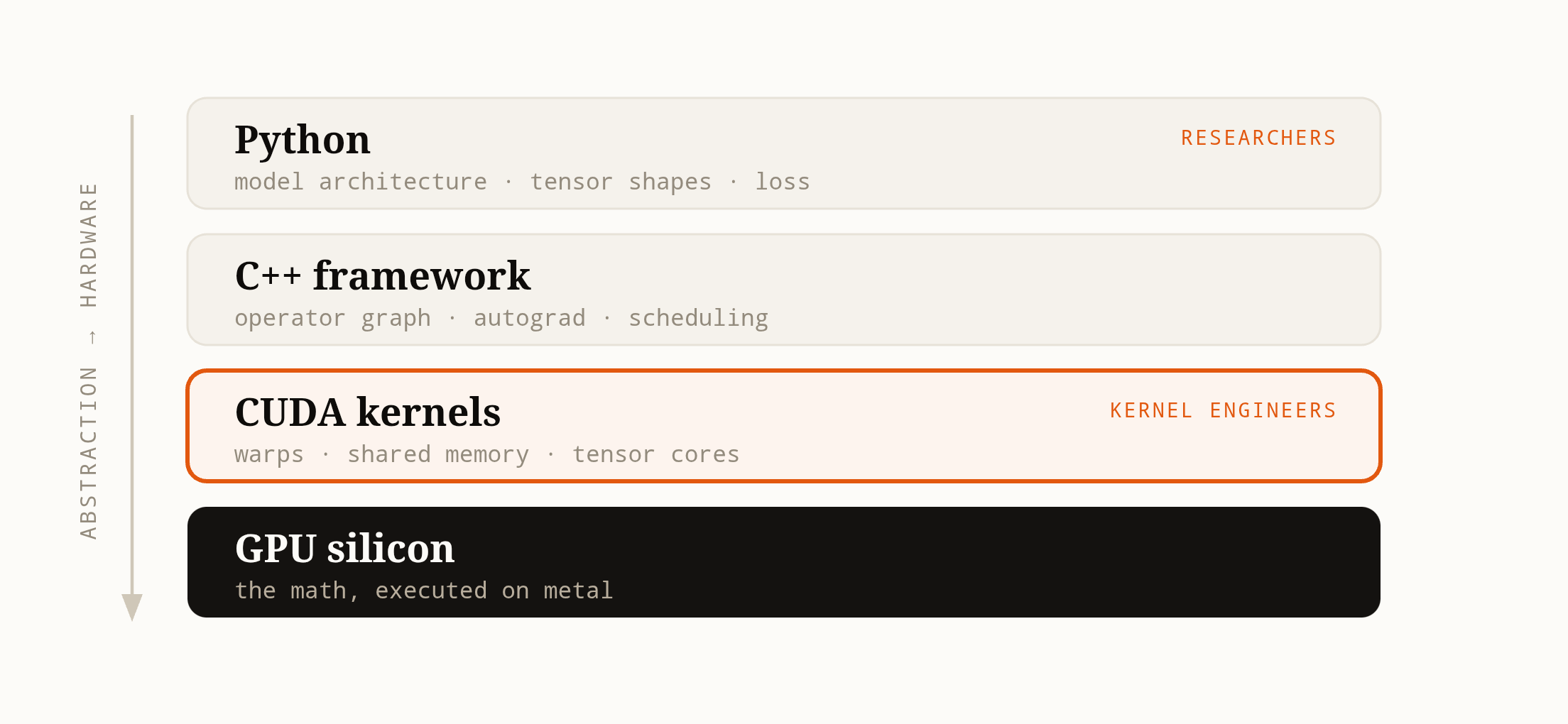
For a long time, this worked great. NVIDIA’s cuDNN5 and cuBLAS6 provided hand-tuned kernels for the most common operations. Standard layers? Great performance, essentially free.
When “Free” Stopped Being Enough
Then ML models stopped being standard.
Attention mechanisms. Custom activation functions. Novel normalization schemes. Mixture-of-experts routing. The architectures that exploded after the 2017 “Attention Is All You Need” paper meant that the operations people needed kept growing faster than any kernel team could keep up with. PyTorch now has thousands of operators. The combinatorial explosion of fusing N of those operations across different hardware is simply not something you can do by hand.
This is when ML compilers showed up.
XLA7 (Accelerated Linear Algebra) was one of the early serious attempts. Built for TensorFlow, later adopted by JAX (where it’s the only execution backend), XLA takes a graph of ML operations and compiles them into optimized code for GPUs, TPUs, and other hardware. It fuses operations, kills redundant computations, optimizes memory layout. A matrix multiply followed by a bias add followed by a ReLU? XLA smashes those into a single kernel launch instead of three. Google trains Gemini on JAX+XLA on TPU pods.
Triton8, created by Philippe Tillet and later brought into OpenAI, went a different direction. Instead of compiling from a graph, Triton gives you a Python-like language for writing kernels where you think in blocks of data instead of individual threads. The compiler handles memory coalescing and thread scheduling. It’s vastly more approachable than raw CUDA, and as of version 3.7.19 (released June 17, 2026), it’s the default kernel generation backend in PyTorch’s torch.compile.
Mojo10, Chris Lattner’s language that aims to be as easy as Python and as fast as C, built on MLIR11 (which Lattner also created). Launched in 2023, hit 1.0 beta in May 202612, and as of yesterday is now part of Qualcomm (more on that shortly). A 2025 paper from Oak Ridge National Laboratory13 found Mojo’s GPU kernels “broadly competitive with CUDA and HIP for memory-bound workloads.”
IREE14 (Intermediate Representation Execution Environment), an MLIR-based compiler and runtime backed by Google and the LF AI & Data Foundation15, targets deployment across everything from data center GPUs to microcontrollers. AMD used an IREE-based implementation for their SDXL MLPerf submission16 in April 2025.
All of these tools share one insight: hand-writing optimized kernels for every combination of operation, hardware, data type, and batch size will never scale. You need a compiler.
The Case for AI-Written Kernels
Then around 2024–2025, large language models got good enough at writing code that people started asking a reasonable question: why build a compiler when you can just ask a model to write the kernel?
Skip the intermediate representations, the optimization passes, the years of compiler engineering. Show the AI the operation spec, the target hardware, some performance constraints. Let it generate CUDA directly. The results so far are hard to dismiss.
Meta deployed it in production. KernelEvolve17, Meta’s agentic kernel coding framework, went live in April 202618 optimizing code serving trillions of daily inference requests. It improved ads model inference throughput by 60% on NVIDIA GPUs, 25%+ training throughput on Meta’s custom MTIA chips. 100% pass rate on all 250 KernelBench19 problems across 480 hardware configurations. Kernel development time went from weeks to hours.
NVIDIA’s own agents beat their own hand-tuned libraries. In March 2026, NVIDIA published AVO20 (Agentic Variation Operators), where autonomous coding agents ran for 7 days evolving multi-head attention kernels on B200 GPUs. They outperformed cuDNN by 3.5% and FlashAttention-4 by up to 10.5%, exploring 500+ optimization directions and hitting 1,668 TFLOPS at BF16.
Community kernel hubs are growing. The HF Kernels library21 launched in beta in June 2025 and became a first-class repository type22 on the Hub in April 2026, sitting alongside Models, Datasets, and Spaces. 61 operators and counting, supporting NVIDIA, AMD, Apple Metal, and Intel. Think “pip install” for GPU kernels, no compilation required.
And the arguments behind this movement are structurally sound:
Transformers won. The dominant ML architecture is, for now, the transformer. Transformers are built from a relatively small set of operations: matrix multiplications, softmax, layer normalization, attention, a handful of activation functions. If you only need to optimize a small set of operations, maybe you don’t need a general-purpose compiler. You need a really good library.
Iteration speed is unmatched. A compiler optimization pass takes months to design, implement, test, and ship. An AI agent generates and benchmarks a new kernel variant in minutes. The CUDA Agent23 system hit 100% faster-than-torch.compile rate on KernelBench Level 1 and Level 2, with 2.11x geometric mean speedup.
Hardware-specific tuning still matters. Compilers aim for generality. They produce “pretty good” code across hardware. FlashAttention-424, written in CuTe-DSL (March 2026), squeezes out performance that automated compilers simply cannot match for the attention operation. ThunderKittens25 (ICLR 2025 Spotlight) showed 85% fewer stalled cycles on shared memory compared to FlashAttention-3 with zero bank conflicts, using warp-level 16x16 matrix tile abstractions.
These are legitimate arguments. They’re also incomplete.
Why Compilers Are More Necessary, Not Less
The Combinatorial Problem
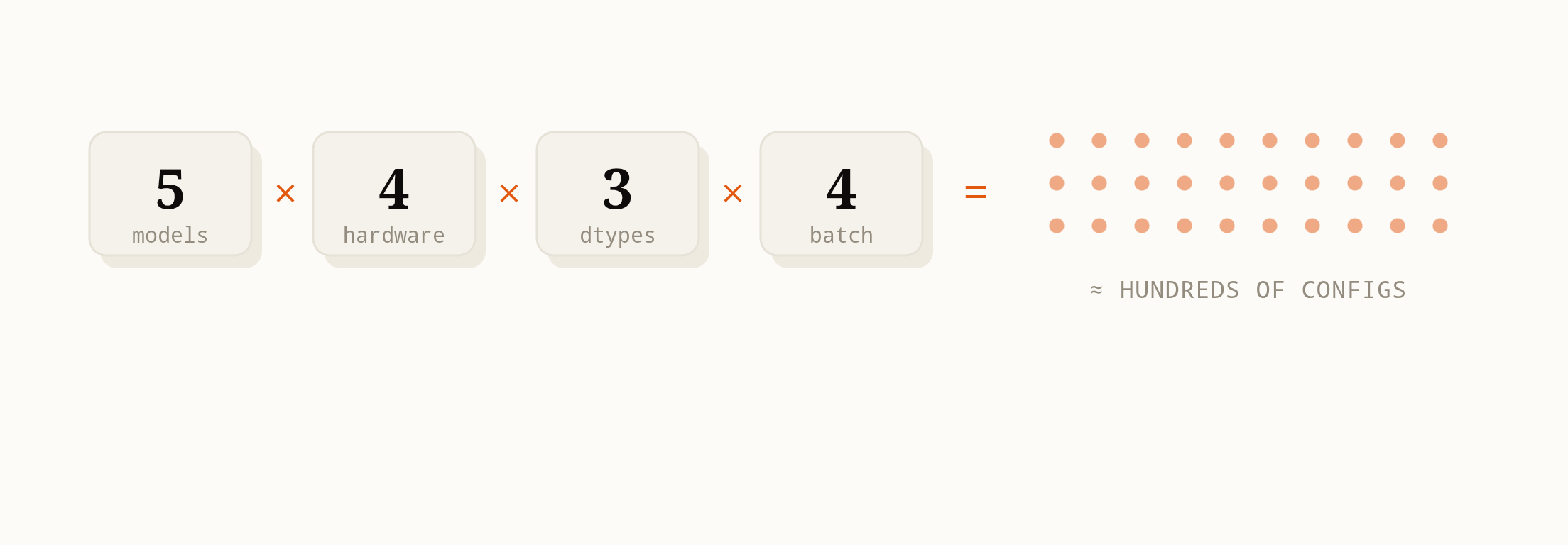
Some napkin math. You’re running an inference service. You’ve got:
5 model architectures (transformer variants, mixture-of-experts, a diffusion model)
4 hardware targets (NVIDIA H100, AMD MI300X, Intel Gaudi 3, your custom ASIC)
3 data types (FP16, BF16, FP8)
4 batch size regimes (single request, small batch, large batch, continuous batching)
Dynamic sequence lengths
That’s hundreds of kernel configurations. And I’m being conservative. In practice, the dimensions interact: the optimal kernel for FP8 on an H100 at batch size 1 looks different from FP8 on an H100 at batch size 64.
You could ask AI agents to generate all of these. But then you need to test each one for correctness (not “does it run” but “does it produce bit-accurate results across all edge cases”). You need to benchmark them. You need to handle the cases where the optimal kernel changes with input shape. You need to maintain all of them when hardware drivers update.
At that point you’ve built a compiler, just a worse one.
The Program Analysis Gap
Compilers don’t just translate code. They analyze it.
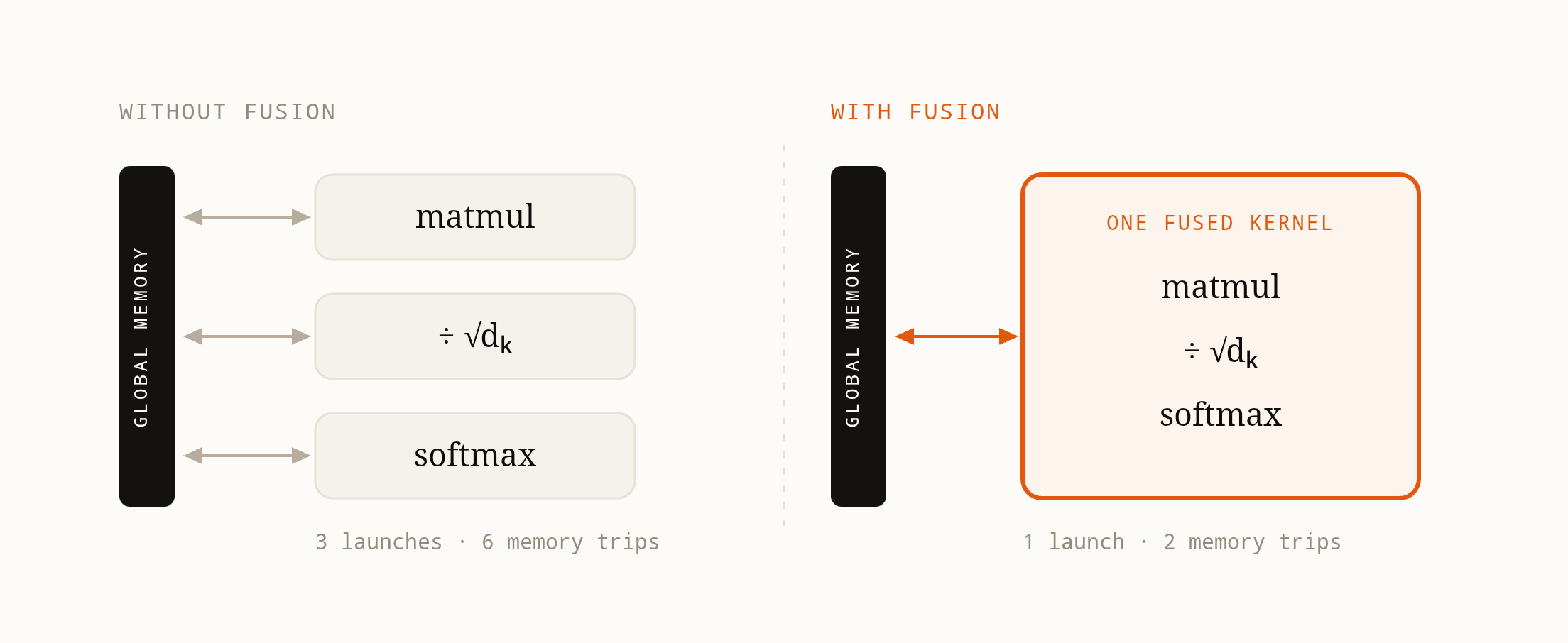
When XLA or Triton’s compiler examines a sequence of operations, it performs operator fusion26: combining multiple operations into a single kernel launch, eliminating the overhead of writing intermediate results to GPU global memory, launching new kernels, reading the results back. For something like softmax(matmul(Q, K^T) / sqrt(d_k)), fusion can deliver 2–5x performance improvement. Your model might chain dozens of such fusible sequences.
Compilers do liveness analysis27 to figure out when tensors can be freed or reused, cutting peak memory consumption. They use polyhedral optimization28 to find optimal tiling and loop scheduling strategies. They verify legality29 before transforming code, making sure that reordering operations doesn’t change the result.
Tiling is like reading a bookshelf: instead of reading page 1 of every book, then page 2 of every book (thrashing your cache constantly), you read each book completely before moving on. Fusion is like cooking: instead of cooking each ingredient in a separate pot, washing all pots, then combining everything, you cook the whole dish in one pot. For memory-bandwidth-bound ML workloads (which most inference is), these optimizations routinely deliver 2x+ speedups.
All of this happens at the computation graph level. An AI agent writing a single kernel can’t fuse it with the operations before and after because it doesn’t see the full computation. You could give the agent the full computation graph and ask it to do all of this. But then you’re asking it to reinvent the compiler, except instead of decades of formal methods backing the transformations, you have “the model seemed pretty confident about this.”
The llama.cpp Lesson
llama.cpp30 was the poster child for hand-written kernels. Georgi Gerganov’s project runs large language models on consumer hardware using purpose-built kernels for ARM NEON, x86 AVX/AVX-512, Apple Metal, Vulkan, and CUDA. Each tuned for specific quantization formats. It runs models that were supposed to require a data center on a MacBook. Separate implementations for every platform, every quantization format (Q4_0, Q4_1, Q5_0, Q5_1, Q8_0, the list goes on). Massive surface area.
Then in April 2026, they rewrote the whole thing31. The biggest architectural change since the project launched. They replaced hand-written SIMD kernels with a compact template layer that emits per-backend code from a shared operator description. Written in plain C, runs at build time. Removed approximately 11,000 lines of duplicated intrinsics.
The result? 70B quantized models got a 2.1x throughput improvement. 70B Q4_K_M on M3 Ultra went from 14.1 to 29.6 tokens per second. The project that most convincingly demonstrated hand-written kernels could beat any compiler decided the approach didn’t scale and moved to a template-based code generator. That’s a compiler by another name. And performance went up, because the new system could apply optimizations consistently across all backends instead of relying on each kernel being independently hand-tuned.
The 1960s portability crisis, replaying in silicon.
The Correctness Problem
A bug in your web app shows the wrong price on a product page. Annoying, fixable.
A bug in a GPU kernel causes silent numerical errors that gradually degrade model quality. It only manifests with specific input shapes, specific batch sizes, on specific hardware revisions. GPU kernel bugs are notoriously hard to diagnose because the execution model is massively parallel and the scheduling is non-deterministic.
Compilers can provide formal guarantees about their transformations. When MLIR applies a tiling transformation, it verifies through dependence analysis29 that the semantics are preserved. An AI agent writing a kernel from scratch provides no such guarantee.
The KernelCraft benchmark32 (March 2026) tested AI agents on emerging hardware ISAs and found that GPT-5.2 achieved only 56% on primitive operations, dropping to near-zero on end-to-end system blocks. Agent-generated code achieved 2.5x compiler baseline speedup versus 20x for human experts on the same task. Documentation quality made a 3x difference in success rate. When you move away from well-documented NVIDIA hardware into the broader ecosystem, the agents’ training data advantage evaporates.
So the technical case for compilers rests on three legs: combinatorial complexity, program-level analysis that no single-kernel generator can replicate, and correctness guarantees that become critical at scale. But you don’t have to take my word for it.
The Industry Placed Its Bets Yesterday
On June 24, 2026, a lot of money moved.
Qualcomm acquired Modular for $3.9 billion. An all-stock deal for the company behind Mojo and the MAX inference engine. Qualcomm CEO Cristiano Amon framed it explicitly as an attack on NVIDIA’s CUDA moat: “the future belongs to developer-friendly, horizontal platforms that can run across diverse compute environments.”33 Modular had last raised $250 million in September 2025 at a $1.6 billion valuation. Qualcomm paid a 2.4x premium for a compiler company. Analyst Yuri Goryunov33: “The key is what Qualcomm actually bought: not silicon, but the software layer.” Though he also cautioned it’s “a multi-year execution play” and that “CUDA’s moat is a decade deep.”
OpenAI unveiled Jalapeno, its first custom AI chip. Co-developed with Broadcom34, manufactured by TSMC, designed specifically for LLM inference. They claim 50% lower cost per token and better performance-per-watt than current GPUs. They used their own frontier models to accelerate the chip design and optimization, achieving design-to-tape-out in 9 months35, which OpenAI calls “the fastest ASIC development cycle ever achieved in high-performance advanced semiconductors.”
But look at how they describe the software stack: “We optimized the architecture around the kernels, memory movement, networking, and serving patterns.” They’re building compilers. They used AI to accelerate compiler development, not to replace it.
NVIDIA’s moat is half compiler. When people talk about CUDA’s36 competitive position, they’re really talking about a compiler toolchain, a runtime, 5.9 million developers, and nearly two decades of accumulated libraries and optimizations. AMD’s ROCm37 has been making steady progress: at MLPerf Inference v6.0, the MI355X posted results within single-digit percentages of NVIDIA B20038 on server inference workloads. Competitive silicon. But the software gap still matters, and what AMD has been pouring money into is compiler infrastructure.
Hardware companies aren’t betting on AI-written kernel libraries. They’re betting on compilers.
AI Makes Compilers Better (And Vice Versa)
The agents in the Fast Gemma Challenge didn’t throw out compiler infrastructure. They used vLLM, SGLang, TensorRT-LLM, torch.compile. They layered optimizations on top of compiler-generated code. The best results came from combining AI creativity with existing compiler and framework infrastructure. Clement Delangue39, Hugging Face’s CEO: “Fun to see the Hub becoming the platform where agents collaborate, just as it became the platform where humans collaborate.”
That pattern keeps showing up. Triton lets you write kernels in a high-level Python-like language that compiles to efficient GPU code. An AI agent that writes Triton kernels instead of raw CUDA gets the productivity of AI-generated code plus the optimization guarantees of the Triton compiler. The agent picks the algorithm. The compiler handles memory coalescing, thread scheduling, hardware-specific lowering. KernelEvolve already supports Triton, CUDA, HIP, CuTe DSL, and FlyDSL as kernel languages. The agents work through compilers.
Meta’s Helion40 takes this further: a higher-level DSL built on top of Triton (now a PyTorch Foundation project) that auto-generates and benchmarks hundreds of Triton kernel variants from a single high-level specification. A compiler generating compiler inputs, optimized by search.
Or consider the compiler’s search problem. When a compiler decides between optimization strategies (tile this loop 32x32 or 64x16? fuse these three ops or keep them separate?), it uses heuristics typically hand-tuned by compiler engineers. AI agents can explore this space much more effectively. This is already happening with learned cost models41 for compiler optimizations. The AI teaches the compiler to make better choices.
The January 2026 survey on LLMs and compilers42 from the research community calls this a “synergy.” Research from Google43 and others showed MLIR-based compilation flows achieve over 90% of hand-optimized kernel performance automatically. The critical 10% of hot kernels benefits from hand-tuning or AI-assisted optimization. But that 10% still runs through compiler infrastructure for lowering, memory management, and cross-kernel optimization. Triton is the convergence point: high-level enough that AI agents write it well, low-level enough that the output competes with hand-tuned kernels, and it’s the default backend in PyTorch’s torch.compile. OpenAI invested in it. Meta builds on top of it. NVIDIA added first-class Blackwell support for it.
If You’re Building ML Infra
Serving one model on one hardware target? Hand-optimized or AI-generated kernels can work. If all you’ll ever run is one transformer on NVIDIA GPUs, a well-tuned kernel library might be all you need.
Anything more complex? You want compiler infrastructure. Multiple models, multiple hardware targets, frequent model changes, custom operations. Each of these dimensions multiplies the maintenance burden until it becomes untenable. This is most of the industry. llama.cpp figured this out and rewrote their entire kernel layer to use code generation instead of hand-written intrinsics. If they can’t sustain the hand-written approach for one model architecture, nobody can.
Either way, pay attention to where the abstractions are moving. The tools that survive will be the ones where AI agents and compilers meet in the middle. Triton is the most visible example today, but the principle is more general: bet on the layer that lets you express intent without micromanaging hardware.
We keep having this argument. A new abstraction appears. The people who are very good at working without it say it’s unnecessary, slow, a crutch. Every time, the abstraction wins. Not because it produces better code than the experts, but because it produces good-enough code for everyone, and the experts find harder problems to solve.
In 1965, a manager at Honeywell noted that while a skilled assembly programmer could still beat COBOL, the question was whether you could find enough such programmers. Today, expert CUDA kernel writers are extremely scarce. There might be a few hundred people worldwide who can write FlashAttention-class kernels. The demand for optimized ML kernels vastly exceeds the supply. AI agents help close that gap, but they do it best when they work through compilers, not around them.
AI-generated kernels are impressive. They’re useful. They’ll keep getting better. But they don’t eliminate the need for compilers any more than autocomplete eliminated the need for programming languages. Kernels work best when combined with the formal analysis, correctness guarantees, and cross-platform portability that compilers provide.
How do we build ML compilers smart enough to take advantage of everything AI agents can do? Qualcomm just answered, yesterday, with a $3.9 billion check to a compiler company.
I write about AI infrastructure, compilers, and low-level systems at maderix.substack.com. If you liked this, you might enjoy my Apple Neural Engine reverse engineering series.
This abstraction debate comes up in many areas, beyond ML compilers, and into areas like robotics (i end up writing about the effects of that pretty often). Another effect of the consolidation is to the ecosystem- would make it really hard for new companies to enter if a monolithic architecture dominates.
I like this piece a lot, and it seems to include a fair amount of LLM-generated prose (based on my impression and a checker program). Can you either correct that impression or, if it is accurate, talk a bit about how you proof-read the LLM prose? I don’t want to recommend something unless the author has checked every sentence.