What Building a Compute Language Taught Me About Compilers
The shift from hoping the compiler guesses right to explicitly guiding it

The SIMD Emission Problem
When I started building SimpLang, a DSL for SIMD hardware optimization, I believed the conventional wisdom: express your computation cleanly, trust the compiler, and modern optimization passes will figure out the rest and make your code run fast in most conditions and on most hardware.
The first problem wasn’t tiling or cache optimization. It was something more fundamental: reliably emitting SIMD instructions at all.
How LLVM’s Vectorizer Actually Works
LLVM has two distinct vectorization strategies, and understanding their limitations was my first lesson in compiler reality.
The Loop Vectorizer (LoopVectorize.cpp) attempts to transform scalar loops into vector operations. It operates in phases:
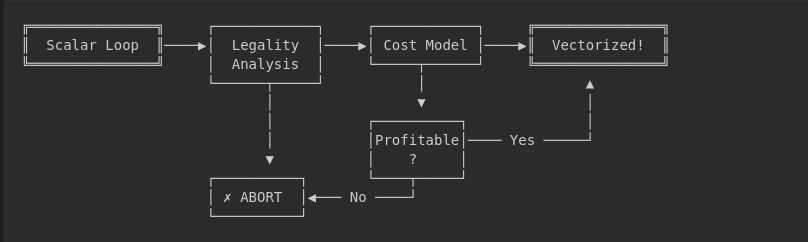
Legality Analysis: Can this loop be vectorized at all? The vectorizer checks for dependencies, function calls, irregular control flow, and memory access patterns. A single
ifstatement with data-dependent branching can disable vectorization entirely.Cost Modeling: LLVM’s
TargetTransformInfo(TTI) provides cost estimates for each instruction on each target. The vectorizer asks: “What’s the cost of a scalarfaddvs a vectorv4f32 fadd?” These costs are heuristic approximations—they don’t account for cache behavior, register pressure in context, or surrounding code.Vectorization Factor Selection: Based on cost estimates, LLVM picks a vector width. But here’s the catch: the cost model optimizes for a single loop in isolation. It can’t see that your 256-bit AVX operations will compete for execution ports with the surrounding code, or that the loop you’re vectorizing feeds into another loop that expects a different layout.
The SLP Vectorizer (Superword Level Parallelism) takes a different approach—it looks for groups of similar scalar operations that could be packed into vectors. But SLP has its own blindspots: it requires nearly identical operations on adjacent memory locations, and it struggles with anything beyond simple straight-line code.
Why Heuristics Fail in Practice
The vectorizer’s decision-making is controlled by thresholds that seemed reasonable to LLVM developers but may be completely wrong for your workload:
// From LLVM's LoopVectorize.cpp (simplified)
static cl::opt<unsigned> VectorizationFactor(
"force-vector-width", cl::init(0), cl::Hidden,
cl::desc("Force vector width for all applicable loops"));
static cl::opt<unsigned> VectorizationInterleave(
"force-vector-interleave", cl::init(0), cl::Hidden,
cl::desc("Force interleave count for all applicable loops"));
These flags exist because even LLVM developers know the heuristics don’t always work. But these are hidden, undocumented, and apply globally. You can’t say “vectorize this loop with width 8, but that loop with width 4.”
Worse, the cost model has fundamental blind spots:
Memory system effects: LLVM assumes memory access costs are uniform. In reality, cache line splits, bank conflicts, and prefetching behavior can make the difference between 10 cycles and 100 cycles for the same instruction.
Cross-iteration dependencies: The vectorizer detects simple recurrences but can’t handle indirect dependencies through memory. If your loop reads from an address computed in the previous iteration, vectorization is disabled even if the addresses are provably non-overlapping.
Backend surprises: The cost model operates on LLVM IR, but final instruction selection happens in the backend. A
shufflevectorthat looks cheap in IR might lower to a sequence ofvperm2f128+vshufpsinstructions that blow your performance budget.
I’ve seen cases where the vectorizer’s decision changed between -O2 and -O3 because the inliner ran differently, exposing different alias analysis results, leading to completely different vectorization choices. Same source code, same compiler version, 3x performance difference based on optimization level.
The Explicit SIMD Solution
To get predictable SIMD behavior, I had to make vector operations explicit in the language:
// Explicit SIMD types - no guessing
var sse1 = make(SSESlice, 1);
var avx1 = make(AVXSlice, 1);
// Direct vector operations
sse1[0i] = sse(1.0, 2.0); // 128-bit SSE vector
avx1[0i] = avx(1.0, 2.0, 3.0, 4.0, 5.0, 6.0, 7.0, 8.0); // 256-bit AVX vector
// Explicit vector arithmetic
slice_set_sse(out, 0i, slice_get_sse(sse1, 0i) + slice_get_sse(sse2, 0i));
With explicit SIMD types—SSESlice for 128-bit vectors, AVXSlice for 256-bit—the compiler no longer guessed. Every vector operation was intentional. But this approach, while predictable, was tedious. Every operation required explicit slice types and accessors. I needed a better abstraction layer.
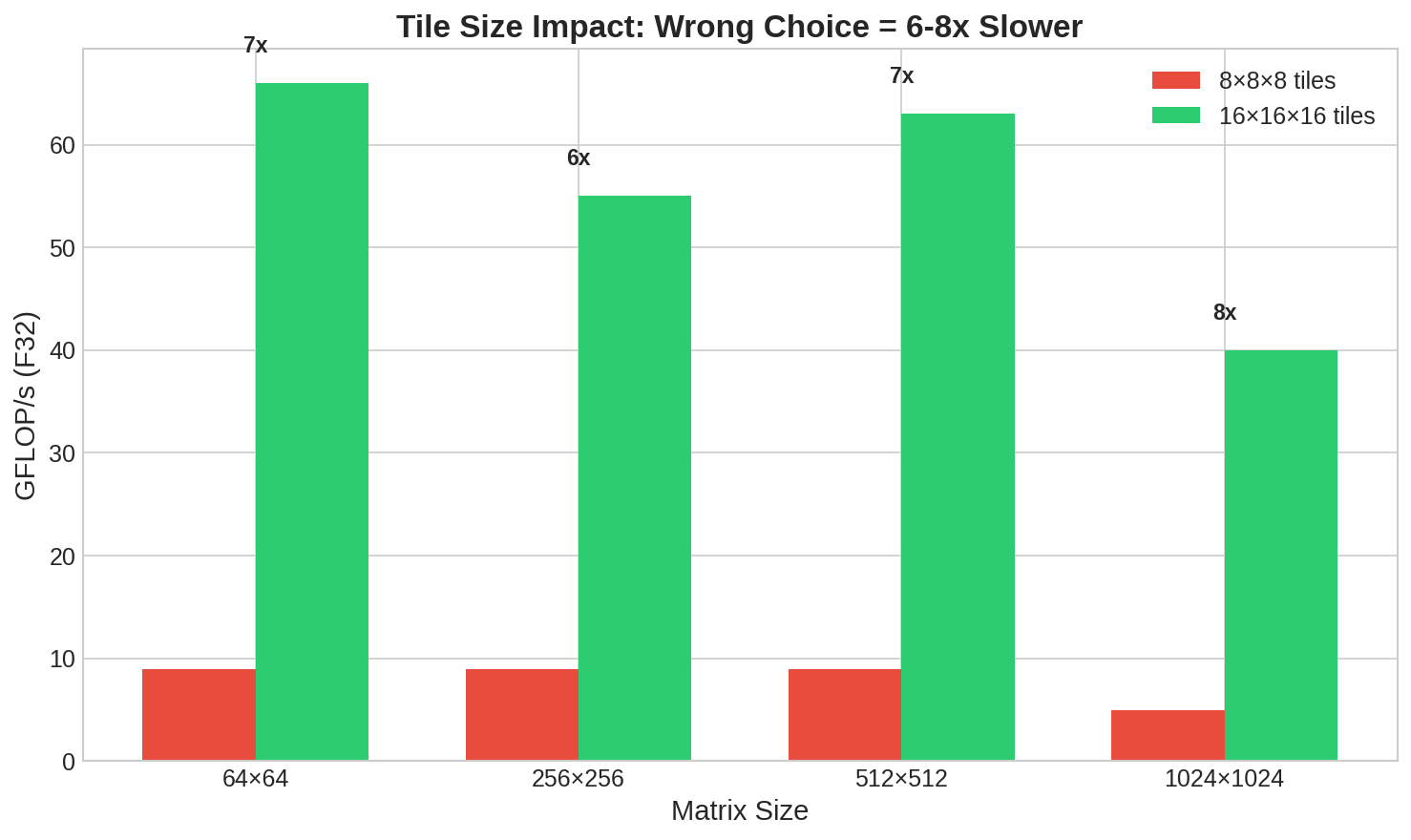
Wrong tile size choice can cost 6-8x performance—information the compiler doesn’t have
MLIR Changed the Dynamic
Introducing MLIR changed everything. The key insight wasn’t that MLIR was faster—it was that MLIR made optimization visible.
The Philosophy of Progressive Lowering
LLVM IR has a fundamental design constraint: it’s a single level of abstraction, low enough to map to machine code but high enough to be target-independent. This “one size fits all” approach means that by the time your code reaches LLVM, you’ve already lost information.
Consider a matrix multiplication. In LLVM IR, it’s just loops over memory:
; LLVM sees this - raw loads, stores, and arithmetic
loop.body:
%a = load float, float* %A.ptr
%b = load float, float* %B.ptr
%mul = fmul float %a, %b
%c = load float, float* %C.ptr
%add = fadd float %c, %mul
store float %add, float* %C.ptr
LLVM doesn’t know this is a matrix multiply. It sees loads, a multiply, an add, and a store. All the structural information—that these operations form a contraction over shared dimensions, that there are specific tiling strategies that work well, that the memory access pattern could be transposed—is gone.
MLIR’s answer is dialects: domain-specific intermediate representations that preserve semantic information through lowering stages.
The Dialect Hierarchy
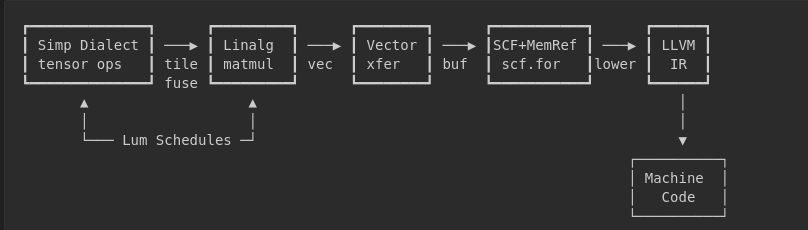
Each level preserves different information:
Linalg Dialect is where the magic happens for dense compute. Linalg represents operations as structured ops—operations with well-defined iteration spaces and access patterns:
// Linalg knows this is a matrix multiply
linalg.matmul ins(%A, %B : tensor<M×K×f32>, tensor<K×N×f32>)
outs(%C : tensor<M×N×f32>) -> tensor<M×N×f32>
The key insight is that linalg.matmul carries its semantics explicitly. The dialect knows:
The iteration space is (M, N, K)
The access patterns are A[i,k], B[k,j], C[i,j]
The reduction dimension is K
Tiling along any dimension is semantically valid
This isn’t pattern-matching to recover structure—the structure was never lost.
Linalg’s Generic Representation goes further. Every structured op can be expressed as a linalg.generic:
linalg.generic {
indexing_maps = [
affine_map<(i, j, k) -> (i, k)>, // A's access pattern
affine_map<(i, j, k) -> (k, j)>, // B's access pattern
affine_map<(i, j, k) -> (i, j)> // C's access pattern
],
iterator_types = ["parallel", "parallel", "reduction"]
} ins(%A, %B : ...) outs(%C : ...) {
^bb0(%a: f32, %b: f32, %c: f32):
%prod = arith.mulf %a, %b : f32
%sum = arith.addf %c, %prod : f32
linalg.yield %sum : f32
}
This representation makes the parallelism structure explicit. The first two iterators are parallel (i and j can execute independently), the third is a reduction (k must accumulate). Tiling transforms can read this information directly.
Tensor vs MemRef: The Bufferization Boundary
MLIR separates what from where through two distinct type systems:
Tensors are value types.
tensor<4x4xf32>represents a 4×4 matrix as an immutable value. Operations on tensors have clean, functional semantics—no aliasing, no side effects.MemRefs are memory references.
memref<4x4xf32>is a pointer to a 4×4 region of memory. Operations on memrefs have imperative semantics—loads and stores with explicit addresses.
The bufferization pass translates from tensor-land to memref-land. This is where MLIR makes decisions that LLVM can never make:
// Before bufferization - pure values
%result = linalg.matmul ins(%A, %B) outs(%C) -> tensor<M×N×f32>
// After bufferization - memory operations
linalg.matmul ins(%A_buf, %B_buf : memref<...>)
outs(%C_buf : memref<...>)
The bufferizer decides buffer allocation, potential in-place updates, and memory reuse. It can prove that %C can be updated in-place because tensor SSA semantics guarantee no other use exists. LLVM’s alias analysis might reach the same conclusion, but it would be reconstructing information that MLIR preserved explicitly.
The Transform Dialect: Meta-Programming Optimizations
MLIR’s Transform Dialect is perhaps its most powerful feature—it lets you express optimization strategies as first-class IR:
transform.sequence failures(propagate) {
^bb0(%arg0: !transform.any_op):
%matmul = transform.structured.match ops{["linalg.matmul"]} in %arg0
// Tile for L2 cache
%tiled, %loops:3 = transform.structured.tile %matmul [64, 64, 64]
// Tile again for registers
%tiled2, %inner:3 = transform.structured.tile %tiled [8, 8, 8]
// Vectorize the innermost tiles
transform.structured.vectorize %tiled2
// Parallelize the outer loops
transform.loop.parallelize %loops#0
}
This isn’t a schedule embedded in the source code—it’s a separate IR that describes how to transform other IR. The same computation can have multiple transform sequences for different targets, different sizes, different contexts.
Measured Results
With this visibility, I could write high-level tensor operations and know exactly what transformations would be applied. More importantly, I could measure:
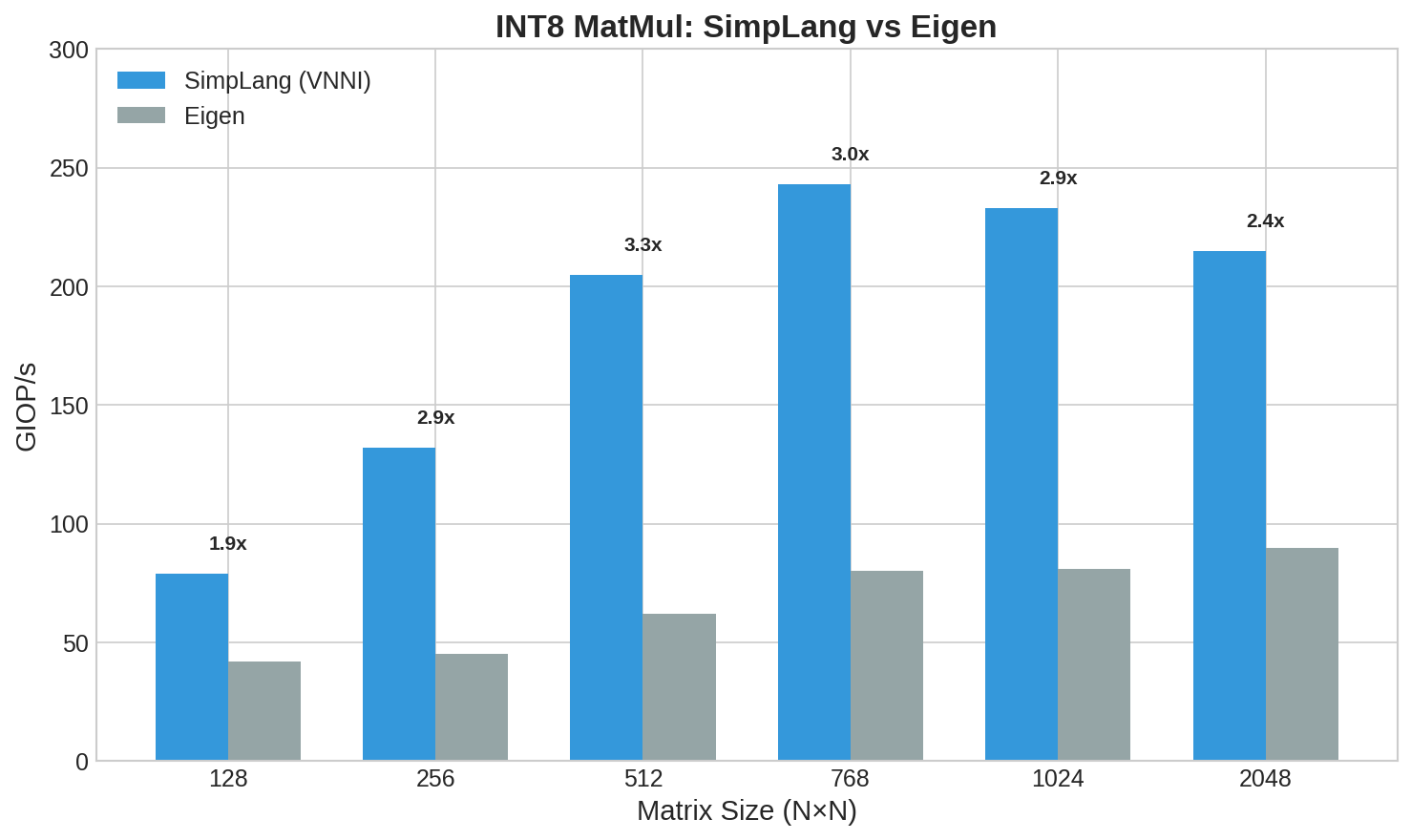
SimpLang wasn’t just matching hand-tuned library code—it was beating Eigen on integer workloads while maintaining near-parity on floating point. The structured IR gave me the control I needed.
SimpLang matching or beating Eigen across matrix sizes
The Quantized Compute Wall
The next wall appeared with quantized compute. Real ML workloads live in int8 and below. On modern x86 hardware, that means VNNI—Vector Neural Network Instructions that can perform 4 simultaneous int8 multiply-accumulates per cycle.
Here, generic compiler optimization became actively harmful.
Understanding VNNI at the Hardware Level
VNNI (introduced in Cascade Lake) added three critical instructions:
vpdpbusd: Multiply unsigned bytes by signed bytes, accumulating into dwordsvpdpwssd: Multiply signed words by signed words, accumulating into dwordsvpdpbusds/vpdpwssds: Saturating variants
The vpdpbusd instruction does something remarkably specific:
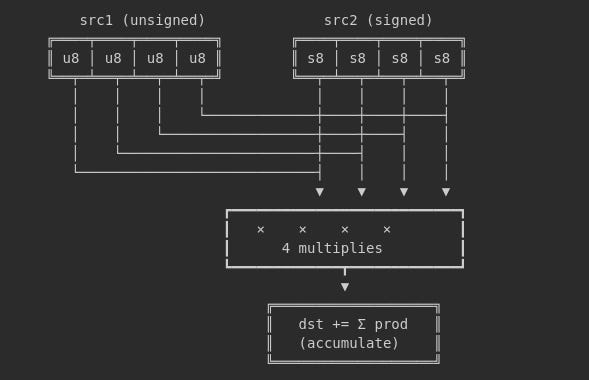
vpdpbusd: 4 int8 multiplies + accumulate into dwordOne instruction performs 4 multiplications and 4 additions with accumulation. With AVX-512, that’s 64 int8 multiplies per instruction across 16 32-bit lanes.
But here’s the critical detail: vpdpbusd expects unsigned × signed operands. Most ML models use signed int8 weights. This mismatch requires careful handling.
Why LLVM’s Optimizations Destroy VNNI Patterns
I had written a clean INT8 matrix multiplication loop. The math was correct. The loop structure was textbook. But LLVM’s -O3 optimization pass, trying to be helpful, restructured the loop nests in ways that destroyed the exact patterns VNNI requires.
Loop Interchange: LLVM’s LoopInterchange pass reorders loop nests to improve cache locality. But VNNI requires a specific reduction order—the K dimension must be innermost and must iterate in steps of 4 to match the 4-way dot product. Interchanging loops breaks the accumulation pattern.
Loop Distribution: LLVM might split a single loop into multiple loops to enable other optimizations. A VNNI loop that loads, multiplies, and accumulates in one body gets distributed into separate load and compute loops—destroying the instruction pattern.
LICM (Loop Invariant Code Motion): Moving “invariant” code out of loops can break the precise register allocation that VNNI requires. The accumulator must stay in a register across iterations; hoisting intermediate computations can force spills.
Reassociation: LLVM’s arithmetic reassociation is perhaps the worst offender. For floating-point code, reassociation is disabled by default (due to non-associativity), but for integers it’s aggressive. Reordering (a + b) + c to a + (b + c) is mathematically equivalent but can destroy the specific reduction tree that maps to vpdpbusd.
The Signed×Signed Problem
VNNI’s vpdpbusd computes unsigned × signed. When both operands are signed (the common case in ML), you need a correction term:
signed_a × signed_b = unsigned_a × signed_b - (a < 0 ? 256 × signed_b : 0)
In practice, this means:
Treat the signed byte as unsigned (just reinterpret the bits)
Compute the unsigned × signed product using
vpdpbusdApply a correction: subtract
256 * sum(b)for each row whereahad negative values
This correction can be precomputed for the weight matrix, but the compiler doesn’t know to do this. Hand-optimizing requires explicit tracking of signedness through the computation.
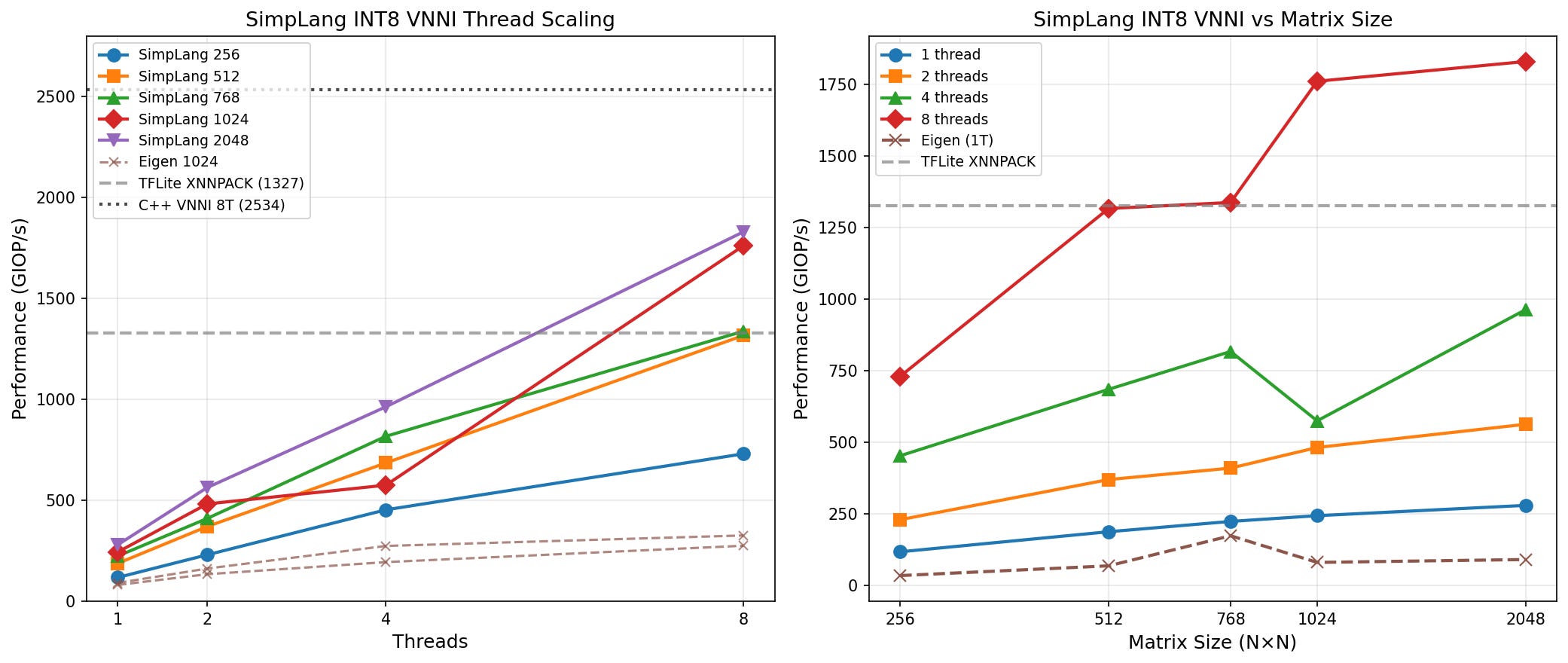
The Impact Was Stark
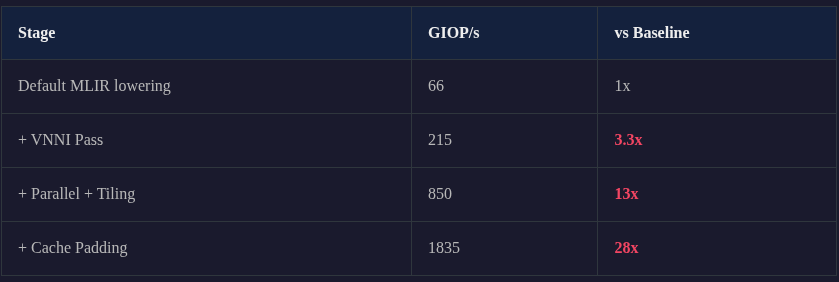
From 66 GIOP/s to 1835 GIOP/s—a 28x improvement on the same hardware, the same algorithm, the same source code. The only difference was how the compiler lowered it.
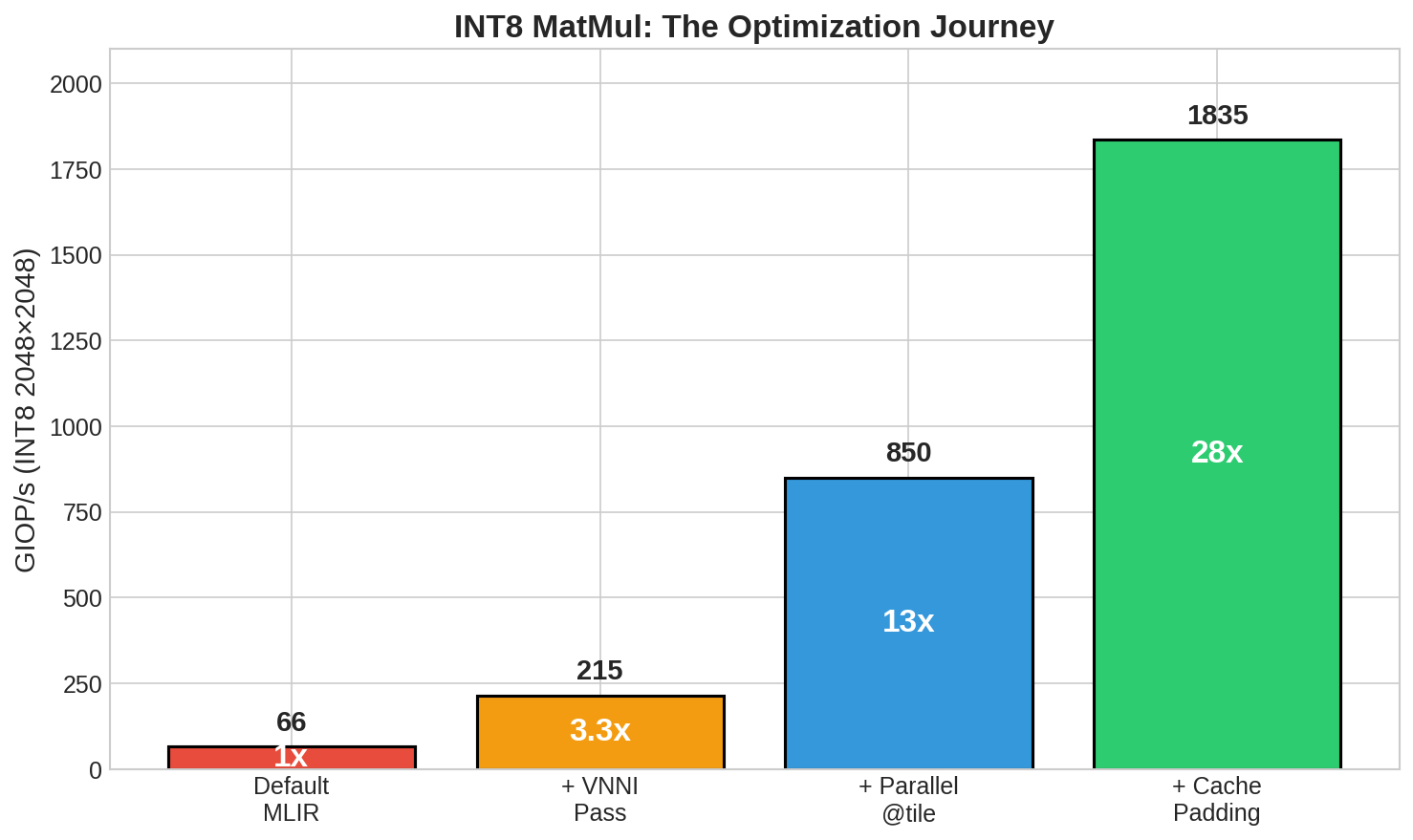
VNNI pass effectiveness: from generic loops to specialized intrinsics
The Workaround That Worked
The workaround that unlocked performance was injecting VNNI-specific lowering before generic optimization passes ran. By the time -O3 sees the code, it’s already been converted to explicit VNNI intrinsics.
Anatomy of the VNNI Pass
The VNNI pass is an LLVM pass that operates on LLVM IR after all MLIR lowering is complete. It pattern-matches the scalar loop structure that MLIR generates for int8 matmul and replaces it with VNNI intrinsics.
1. Pattern Detection: The pass walks LLVM functions looking for nested loops with i8 multiply-accumulate patterns:
// LLVM FunctionPass - operates on LLVM IR, not MLIR
bool runOnFunction(Function &F) override {
// Look for loops with i8 load → multiply → i32 accumulate pattern
for (Loop *L : LI) {
if (isInt8DotProductLoop(L)) {
rewriteToVNNI(L);
}
}
}
The pattern matcher looks for:
load i8instructions loading from contiguous memorysext i8 to i32sign extensionsmul i32multiplicationsadd i32accumulation into a phi node
2. K=4 Tiling: VNNI accumulates 4 int8 products per instruction. The K dimension is tiled to 4 at the MLIR level via @lower("vnni.i8_matmul") annotation, which ensures the loop structure matches what the LLVM pass expects:
// At MLIR level (AnnotationLoweringPass), K is tiled to 4:
// This creates the loop structure: for k_outer { for k_inner=0..4 { ... } }
SmallVector<int64_t> tileSizes = {1, 16, 4}; // M=1, N=16, K=4
The N=16 tile corresponds to the number of 32-bit lanes in AVX-512 (16 dword accumulators).
3. Signed Arithmetic Handling: For signed × signed, the LLVM pass computes the bias correction:
// VNNI's vpdpbusd expects unsigned × signed
// For signed × signed: result = vpdpbusd(a_as_unsigned, b) - correction
// where correction = 256 * sum(b) for negative a values
Value *correction = computeSignedCorrection(AVec, BVec);
Acc = Builder.CreateSub(Acc, correction);
4. Intrinsic Emission: The pass emits LLVM intrinsics directly:
// Emit the vpdpbusd intrinsic
Value *Result = Builder.CreateIntrinsic(
Intrinsic::x86_avx512_vpdpbusd_512,
{},
{Accumulator, AVec, BVec} // dst, src1 (unsigned), src2 (signed)
);
5. Horizontal Reduction: After the K-loop completes, reduce the vector lanes:
// AVX-512: reduce 16 lanes to a single i32
Value *Reduced = Builder.CreateIntrinsic(
Intrinsic::vector_reduce_add,
{VectorType::get(Int32Ty, 16)},
{VNNIResult}
);Pass Ordering is Critical
The VNNI pass must run at a specific point in the pipeline:
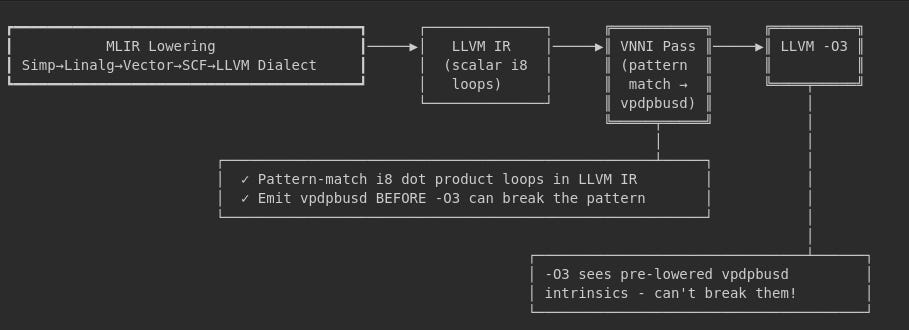
// MLIR pipeline runs first (all phases)
mlirPipeline.runPasses();
auto llvmModule = mlirPipeline.translateToLLVMIR(llvmContext);
// THEN at LLVM IR level, run VNNI pass BEFORE O3
llvm::legacy::PassManager vnniPM;
vnniPM.add(llvm::createLoopSimplifyPass()); // Create proper preheaders
vnniPM.add(llvm::createLCSSAPass()); // Loop closed SSA form
vnniPM.add(llvm::createVNNIPass()); // Pattern-match → vpdpbusd
vnniPM.run(*llvmModule);
// NOW run O3 - it sees the already-lowered intrinsics
auto optPipeline = mlir::makeOptimizingTransformer(3, 0, targetMachine);
optPipeline(llvmModule.get());
The VNNI pass works at the LLVM IR level because it needs to pattern-match the specific loop structure that MLIR generates for int8 matmul, then replace it with vpdpbusd intrinsics before O3 can reorganize the loop.
The Result
On 4096×4096 INT8 matrices with 8 threads:
2031 GIOP/s (~2 TOPS)
That’s 79.3% of theoretical peak on an Ryzen 7 7800x3d processor
Memory bandwidth, not compute, becomes the bottleneck
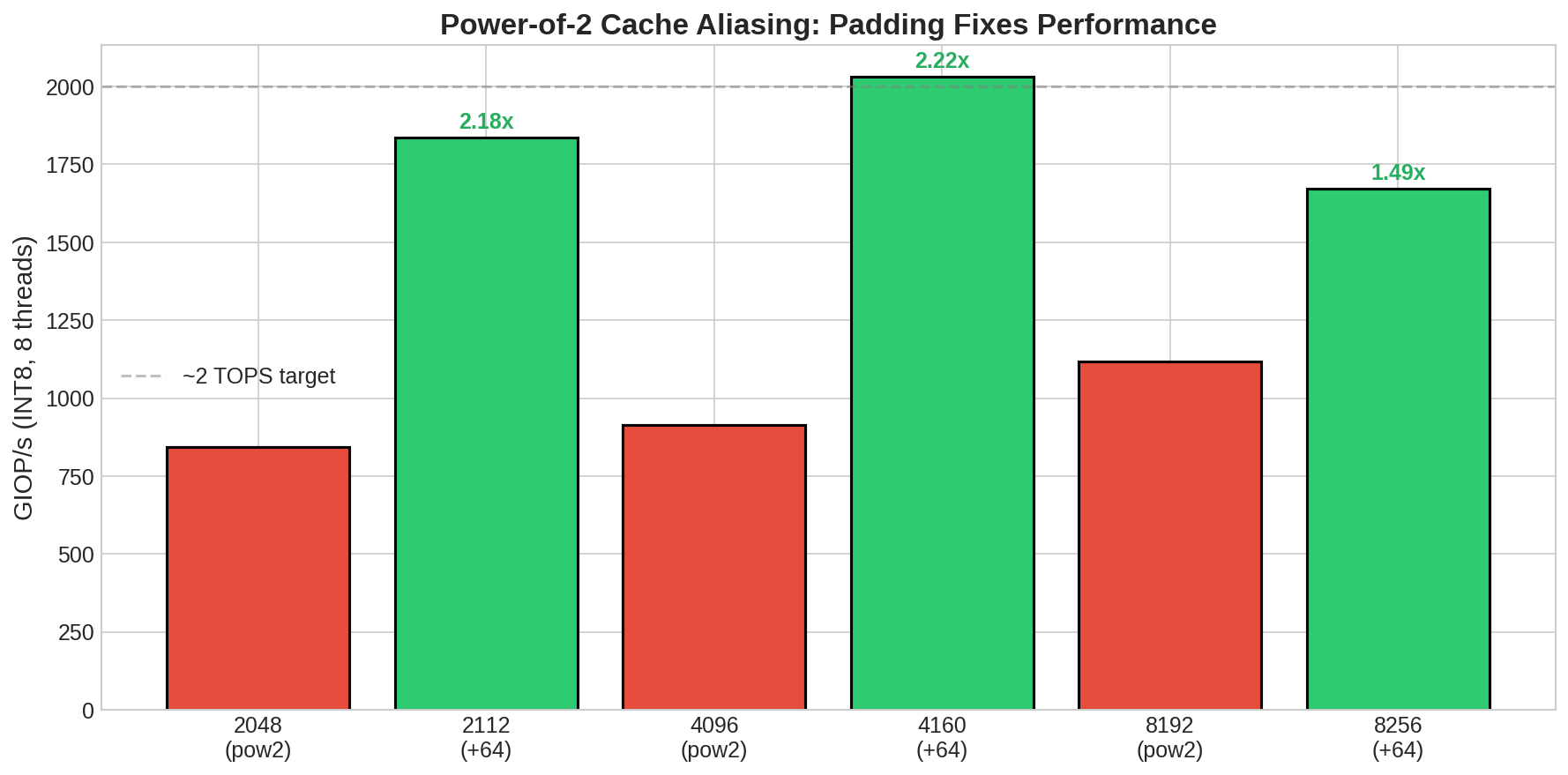
Power-of-2 cache aliasing: 4096 vs 4160 = 2.2x difference
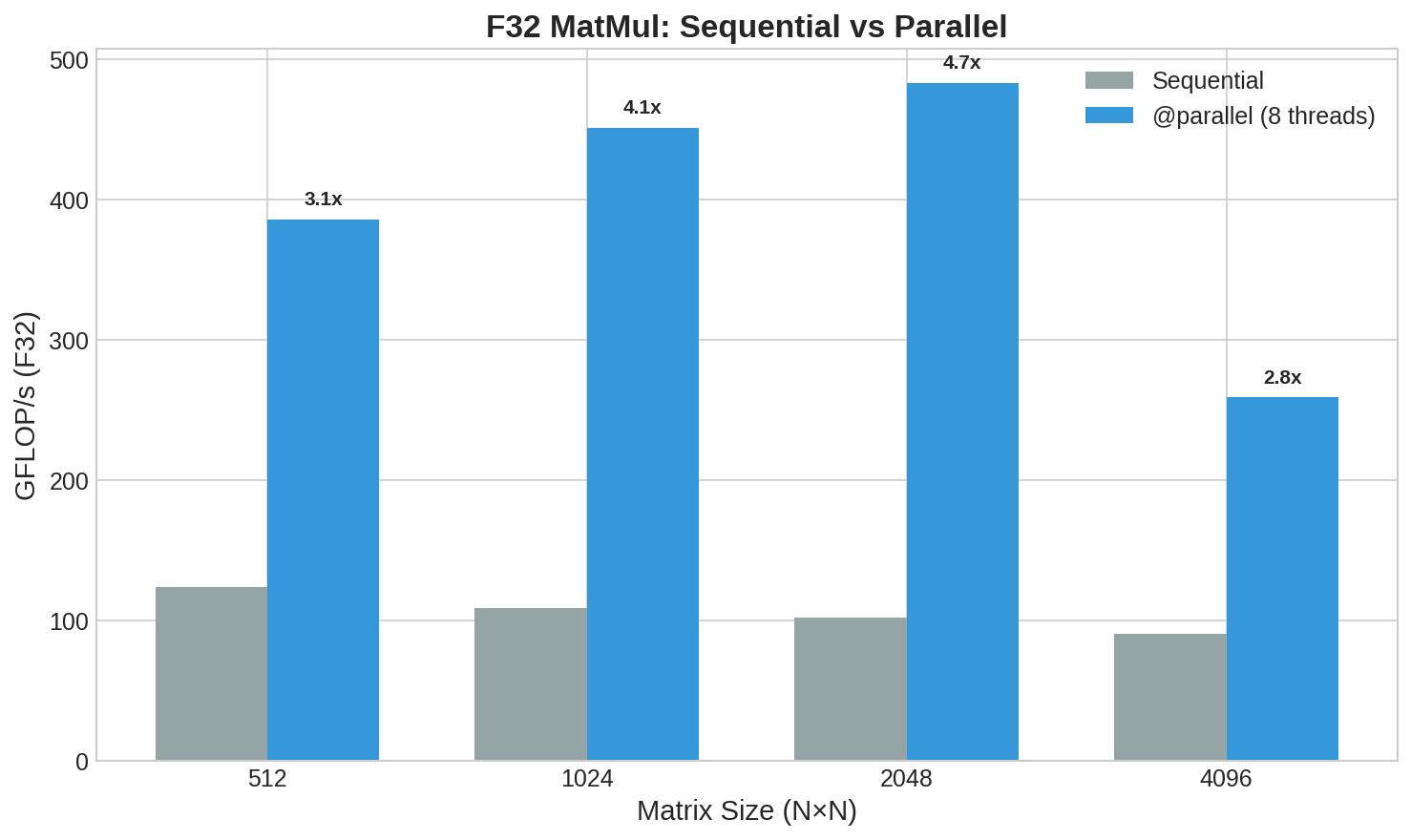
Thread scaling: near-linear on large matmuls, overhead-dominated on small ones
This wasn’t academic optimization. It translated directly to real workloads.
The Real Realization
At this point I had fast kernels—but they were fragile. Every matrix size, every thread count, every target CPU required re-tuning. Handwritten kernels are a local maximum. You can tune a specific kernel for a specific size on specific hardware, but the optimization doesn’t transfer.
The core problem isn’t code generation. It’s preserving intent across lowering stages.
The Hidden Cost of Bad Defaults
Consider these seemingly innocent choices:
Tile size: 8×8×8 vs 16×16×16 = 8x performance difference
The optimal tile size depends on L1 cache size (32KB), L2 cache size (256KB-1MB), vector register count (32 ZMM registers on AVX-512), and the specific matrix dimensions. LLVM picks based on cost model heuristics that don’t know your cache hierarchy.
Power-of-2 cache aliasing: 4096 vs 4160 = 2.2x difference
When matrix dimension equals a power of 2, cache set conflicts become catastrophic. Column j and column j+4096 map to the same cache lines. Adding 64 bytes of padding (4160 instead of 4096) eliminates the conflict.
Loop ordering: IJK vs JIK = 4x difference on cache-unfriendly sizes
For A[i,k] × B[k,j] → C[i,j]:
IJK order: A has stride-1 access, B has stride-N access (cache-hostile)
JIK order: B has stride-1 access, but C has stride-N access
IKJ order: Both A and C have stride-1 access (optimal for row-major storage)
The compiler can’t know these things. But I can. What I needed was a way to express this knowledge separately from the computation itself.
Schedules as the scalable Solution
This led to Lum—a domain-specific language for expressing optimization schedules. Lum compiles to MLIR’s Transform Dialect, providing structured transformation primitives.
The Halide Insight
Lum draws heavily from Halide’s scheduling philosophy. Halide proved that separating algorithm from schedule enables:
Portability: Same algorithm, different schedules for different targets
Explorability: Try many optimization strategies quickly
Composability: Combine transformations without manual code surgery
But Halide schedules are embedded in C++, tightly coupled to Halide’s own IR. Lum targets MLIR’s Transform Dialect, making it composable with the broader MLIR ecosystem.
Lum Schedule Syntax
schedule VNNIOptimized(Int8Matmul) {
// First-level tiling for L2 cache locality
tile [32, 32, 64] => m, n, k
// Second-level tiling for registers / VNNI granularity
tile [1, 16, 4] => _, micro_n, micro_k
// Vectorize with VNNI-specific lowering
vec [16, 4] vnni
// Parallelize the outer M tiles
parallel m
// Prefetch next tile during current computation
prefetch k offset=1
}
Each line compiles to Transform Dialect operations:
transform.sequence failures(propagate) {
^bb0(%arg0: !transform.any_op):
// tile [32, 32, 64] => m, n, k
%matmul = transform.structured.match ops{["linalg.matmul"]} in %arg0
%tiled_l2, %m_loop, %n_loop, %k_loop =
transform.structured.tile %matmul [32, 32, 64]
// tile [1, 16, 4] => _, micro_n, micro_k
%tiled_reg, %_, %micro_n, %micro_k =
transform.structured.tile %tiled_l2 [1, 16, 4]
// vec [16, 4] vnni
transform.structured.vectorize %tiled_reg {vnni = true}
// parallel m
%parallel_m = transform.loop.parallelize %m_loop
}
Inline Annotations for Simpler Cases
For simpler cases where you don’t need full Lum schedules, SimpLang supports inline annotations. These are particularly useful for F32 workloads where you want to control tiling and parallelization:
Without annotations:
// Default behavior - compiler guesses
var C = tensor_matmul(A, B);
With annotations:
// Explicit optimization control
@parallel @tile(64, 64, 64)
var C = tensor_matmul(A, B);

How Annotations Lower to Transform Dialect
Each annotation becomes a transform operation:
// @tile(64, 64, 64) lowers to:
%tiled, %loops:3 = transform.structured.tile %op [64, 64, 64]
// @parallel lowers to:
transform.loop.parallelize %loops#0
// @prefetch(4) lowers to:
transform.loop.prefetch %loops#2 {distance = 4}
// @unroll(4) lowers to:
transform.loop.unroll %inner {factor = 4}
The beauty is that these transformations compose. The Transform Dialect handles ordering, validity checking, and error propagation. If a transformation fails (e.g., trying to tile a dimension that doesn’t exist), you get a clear error message, not silent miscompilation.
The Performance Difference
// Without schedule: 66 GIOP/s
var C = tensor_matmul(A, B);
// With schedule: 2031 GIOP/s
@parallel @tile(32, 64, 16) @lower("vnni.i8_matmul")
tensor_matmul_out(A, B, C);
30x performance difference from the same computation. The only change is metadata telling the compiler how to lower it.
Real-World Validation: LLaMA INT8
These optimizations weren’t academic exercises. I implemented complete LLaMA transformers with INT8 quantized weights to validate end-to-end performance.
The demo above shows stories110M running interactively. For production benchmarks, I tested the larger LLaMA 3.2-1B model:
Thread Scaling Results (LLaMA 3.2-1B)
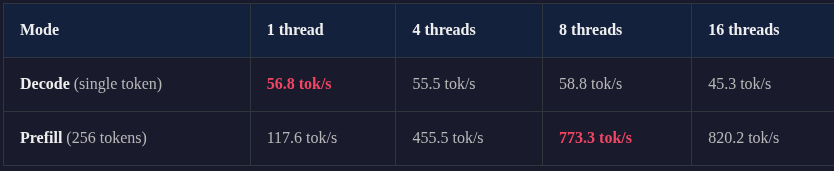
Key observations:
Single-threaded decode hits 56.8 tok/s — VNNI intrinsics alone are powerful enough for interactive use
Prefill scales ~6.6x from 1 to 8 threads (near linear scaling)
Decode doesn’t benefit from parallelism — thread synchronization overhead hurts small matmuls
8 physical cores is optimal — SMT (16 threads) adds contention without benefit
Memory footprint: ~928 MB for the full 1B parameter model in INT8.
Why Prefill Scales But Decode Doesn’t
The decode vs prefill distinction matters:
Prefill processes the entire prompt in one shot. With 256 tokens and hidden dimension 2048, each attention layer performs a (256 × 2048) × (2048 × 2048) matrix multiply. That’s 1 billion multiply-accumulates—enough work to amortize thread synchronization overhead across 8 cores.
Decode processes one token at a time. Each step is a (1 × 2048) × (2048 × 2048) multiply—a matrix-vector product. With only 4 million operations per layer, the ~10μs overhead of thread barriers dominates. Single-threaded execution with VNNI is actually optimal.
This is why separate schedules matter:
// Prefill schedule: maximize parallelism
schedule PrefillOptimized(Attention) {
tile [64, 64, 64] => m, n, k
parallel m
vec [16, 4] vnni
}
// Decode schedule: minimize overhead
schedule DecodeOptimized(Attention) {
tile [1, 256, 4] => m, n, k // Full N-tile, no parallelism
vec [16, 4] vnni
// No @parallel - single thread is faster
}
The same model, the same weights, different schedules for different execution contexts.
The Shift
That shift—from hoping the compiler guesses right to explicitly guiding it—is the most important thing building a compute language taught me about compilers.
The fantasy of “sufficiently smart compilers” that automatically extract optimal performance from clean code is appealing but misleading. Real performance requires understanding the interaction between algorithms, data layouts, memory hierarchies, instruction sets, and runtime characteristics. No amount of static analysis can recover information that was never expressed in the source code.
What Compilers Can and Cannot Do
Compilers excel at:
Local optimizations: Dead code elimination, constant folding, strength reduction
Register allocation: Mapping virtual registers to physical ones (graph coloring, linear scan)
Instruction selection: Choosing opcodes that match semantics
Peephole optimization: Replacing instruction sequences with better ones
Compilers struggle with:
Algorithm selection:
O(n²)vsO(n log n)looks the same at the IR levelData layout: Row-major vs column-major, AoS vs SoA requires semantic knowledge
Tiling for cache: Without knowing cache sizes and access patterns, all tiles look equivalent
Specialized hardware: VNNI, Tensor Cores, AMX require explicit targeting
The answer isn’t to abandon compilers and hand-write assembly. It’s to give compilers the information they need—through schedules, annotations, and structured intermediate representations—so that the intent survives the journey from source to silicon.
The Compiler as Collaborator
MLIR’s Transform Dialect represents a paradigm shift in compiler design.
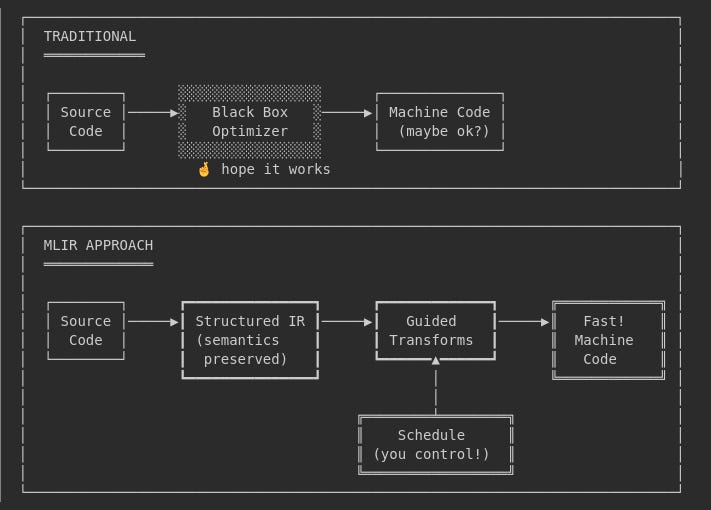
Instead of hoping the optimizer guesses right, we tell it what we want through schedules and annotations. The programmer retains control. The compiler handles the mechanical details. Neither is trying to do the other’s job.
The compiler is a collaborator, not a black box. The better you can express your intent, the better it can help you achieve it.